yolov5 yolo是一个用于目标模块检测的单阶段模型。目前Ultralytics LLC团队已经发布了yolov5-6.0 。虽然目前yolov5还没有作为一个大版本合并到原始的yolo项目中,但是yolov5在目标模块检测任务中有着更好的表现,因此选择yolov5作为车辆检测任务的模型。
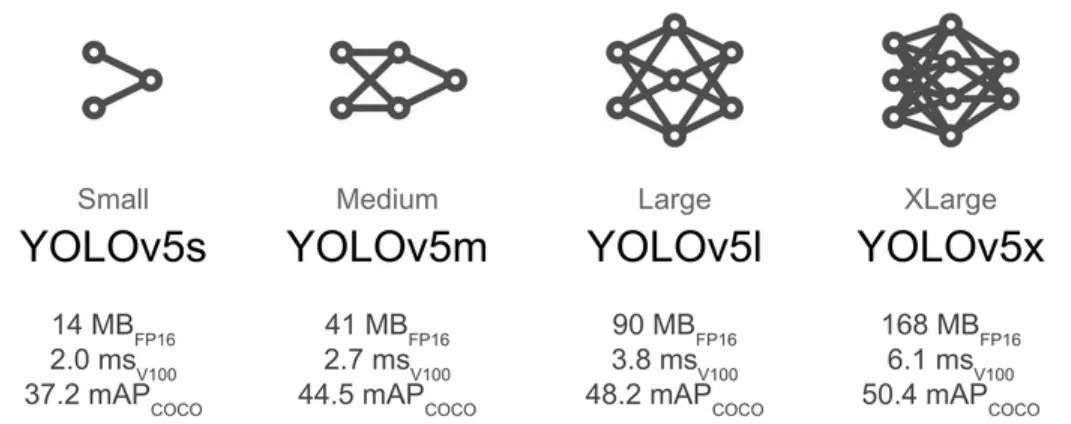
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x。各个模型之间的差别主要体现在网络的深度和宽度上。受限于训练时间和训练平台,此次车辆检测任务中选择使用yolov5s模型来进行数据集的训练任务。
UA-detrac数据集 原始的UA-detrac数据集中包含着丰富且详尽的数据标签,完整的训练数据集>=5G,如果使用全部的数据参与训练,会大大增加训练的时间以及训练所要求的硬件配置。因此对该数据集进行了一定程度上的裁剪,并只保留了标签中的种类信息。并且,原始数据集的格式不符合yolov5处理数据的要求,需要对该数据集进行处理。首先将其转换为VOC格式的数据,之后可以利用下面的pyhton代码,将VOC格式转换成yolo所需的格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 %cd /home/aistudio/work/VOCdata/ import osimport randomtrainval_percent = 0.1 train_percent = 0.9 xmlfilepath = '/home/aistudio/work/VOCdata/Annotations' if not os.path.exists('ImageSets/' ): os.makedirs('ImageSets/' ) total_xml = os.listdir(xmlfilepath) num = len (total_xml) list = range (num)tv = int (num * trainval_percent) tr = int (tv * train_percent) trainval = random.sample(list , tv) train = random.sample(trainval, tr) ftrainval = open ('ImageSets/trainval.txt' , 'w' ) ftest = open ('ImageSets/test.txt' , 'w' ) ftrain = open ('ImageSets/train.txt' , 'w' ) fval = open ('ImageSets/val.txt' , 'w' ) for i in list : name = total_xml[i][:-4 ] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftest.write(name) else : fval.write(name) else : ftrain.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()
这里主要进行的工作是对训练数据和验证数据的划分,按照9:1的比例来划分训练数据和验证数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 %cd /home/aistudio/work/VOCdata/ import xml.etree.ElementTree as ETimport pickleimport osfrom os import listdir, getcwdfrom os.path import joinsets = ['train' , 'test' ,'val' ] Imgpath = '/home/aistudio/work/VOCdata/images' xmlfilepath = '/home/aistudio/work/VOCdata/Annotations/' ImageSets_path='ImageSets/' classes = ['car' , 'bus' , 'van' , 'others' ] def convert (size, box ): dw = 1. / size[0 ] dh = 1. / size[1 ] x = (box[0 ] + box[1 ]) / 2.0 y = (box[2 ] + box[3 ]) / 2.0 w = box[1 ] - box[0 ] h = box[3 ] - box[2 ] x = x * dw w = w * dw y = y * dh h = h * dh return (x, y, w, h) def convert_annotation (image_id ): in_file = open (xmlfilepath+'%s.xml' % (image_id)) out_file = open ('labels/%s.txt' % (image_id), 'w' ) tree = ET.parse(in_file) root = tree.getroot() size = root.find('size' ) w = int (size.find('width' ).text) h = int (size.find('height' ).text) for obj in root.iter ('object' ): difficult = obj.find('difficult' ).text cls = obj.find('name' ).text if cls not in classes or int (difficult) == 1 : continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox' ) b = (float (xmlbox.find('xmin' ).text), float (xmlbox.find('xmax' ).text), float (xmlbox.find('ymin' ).text), float (xmlbox.find('ymax' ).text)) bb = convert((w, h), b) out_file.write(str (cls_id) + " " + " " .join([str (a) for a in bb]) + '\n' ) wd = getcwd() print(wd) for image_set in sets: if not os.path.exists('labels/' ): os.makedirs('labels/' ) image_ids = open (ImageSets_path+'%s.txt' % (image_set)).read().strip().split() list_file = open ('%s.txt' % (image_set), 'w' ) for image_id in image_ids: list_file.write(Imgpath+'/%s.jpg\n' % (image_id)) convert_annotation(image_id) list_file.close()
基于生成的测试数据和验证数据,根据对应的xml文件中的内容生成yolo格式的标签,并将训练数据和验证数据所使用的图片的文件路径写入文件中,使得训练模块和验证模块可以正确读取数据。
训练平台 使用百度提供的AI studio平台进行本次任务的训练。由于AI studio平台不再支持pytorch框架的稳定运行,因而不能直接使用原始的基于pytorch框架编写的yolov5项目进行训练。训练基于paddlepaddle框架重新编写的yolov5项目 ,以实现使用AIStudio高性能环境快速构建YOLOv5训练。
训练以及可视化 完成相关文件中数据集路径以及label路径的修改,使用下面的命令即可进行数据的训练任务:
1 2 %cd /home/aistudio/work/ !python train.py --img 640 --epochs 30 --batch 64 --data ./data/vehicle.yaml --cfg yolov5s.yaml --weights ./weights/yolov5s.pdparams
可以在命令后面追加参数--resume Ture来继续训练中断的任务
AI studio平台提供了后台任务的功能,这样就不用一直挂机notebook环境了。虽然我试着用了一下并没有成功
数据训练使用的ymal文件如下:
1 2 3 4 5 6 7 train: ./VOCdata/train.txt # voc_annotation.py生成的train.txt的路径 val: ./VOCdata/val.txt # voc_annotation.py生成的val.txt的路径 test: ./VOCdata/test.txt # voc_annotation.py生成的val.txt的路径 # Classes nc: 4 # number of classes names: ['car','bus','van','others'] # class names
参数解释:
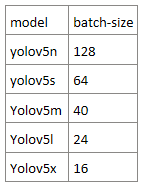
epochs: 轮数,需要指定,默认为300,本次车辆检测使用预训练模型,30轮训练即可达到不错的检测精度;batch: 一次处理多少数据,一次处理128个数据大概占用23.9G显存img: 训练和测试数据集的图片尺寸,默认640,640data: 数据集配置文件,已经修改好data/vehicle.yaml文件,如果本地训练请自行修改参数,并准备好数据集
显卡为Tesla V100 16G下batch 设置参考表:
32G显存请翻倍
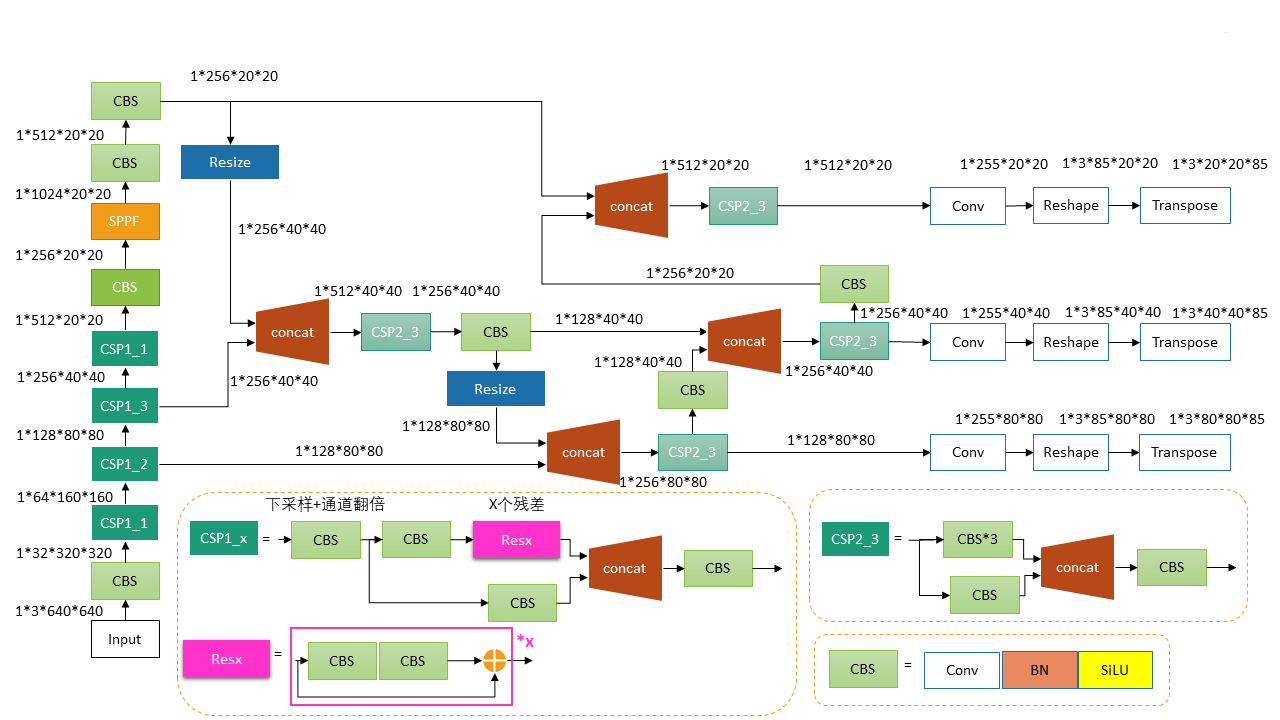
模型的网络结构图如下所示:
这里
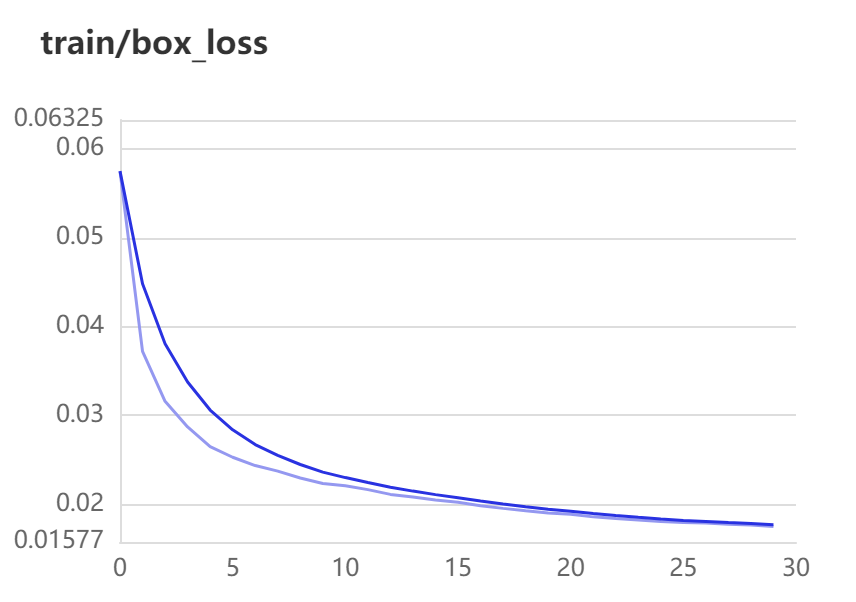
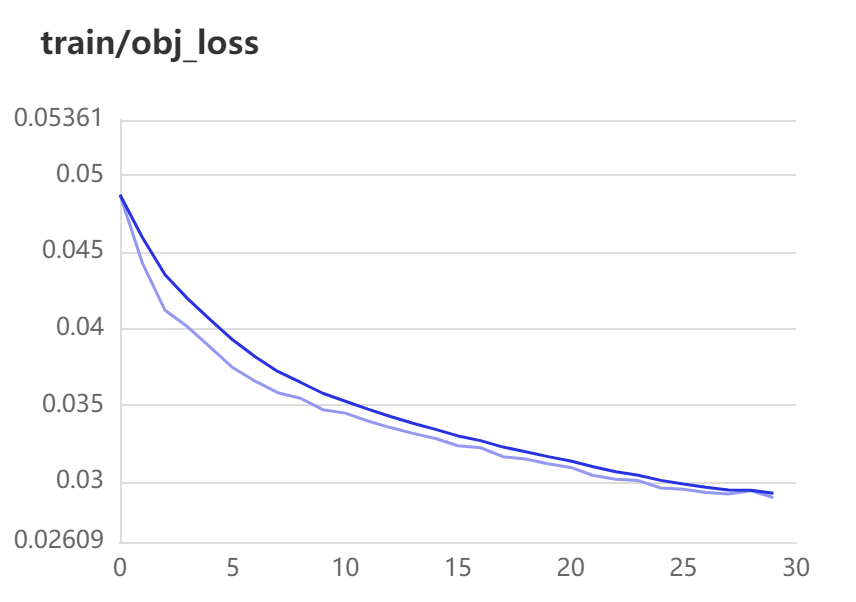
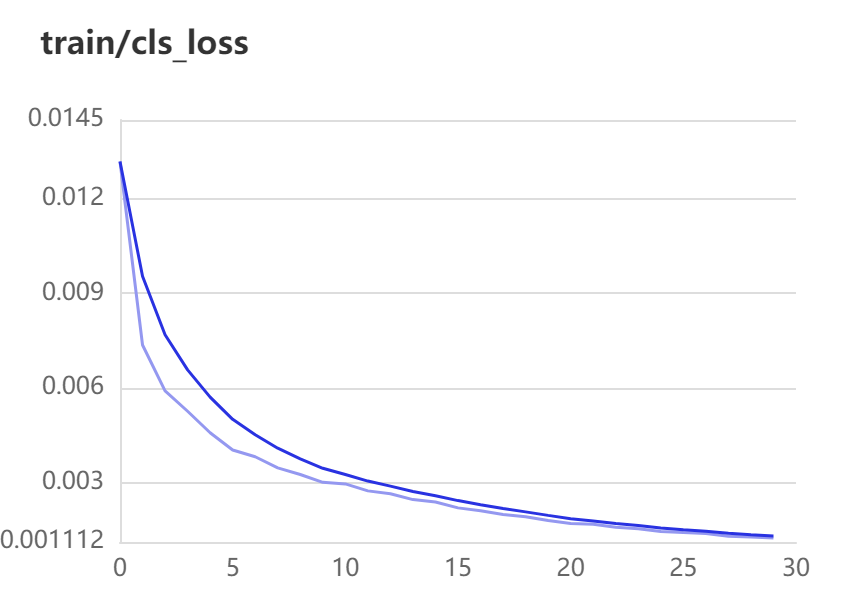
train-loss:
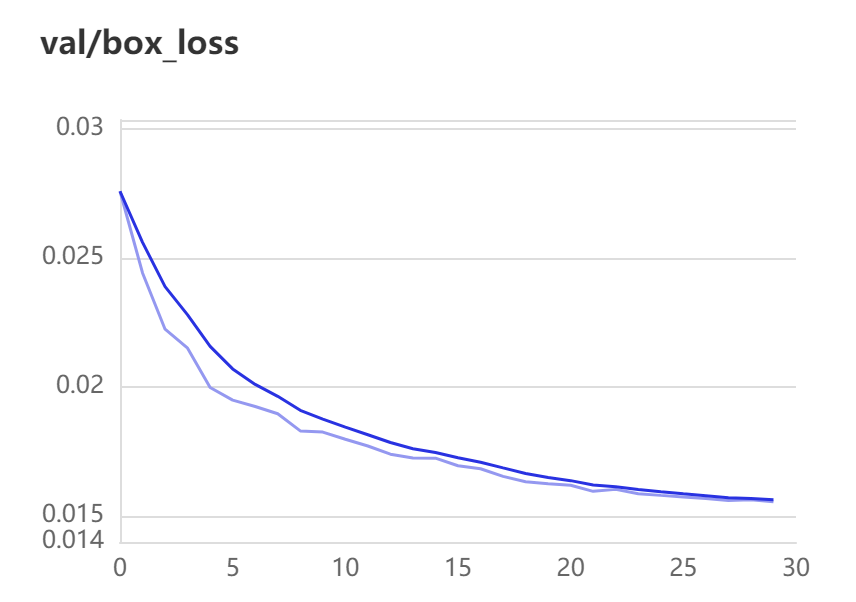
一个是xywh部分带来的误差,也就是box带来的loss
一个是置信度带来的误差,也就是obj带来的loss
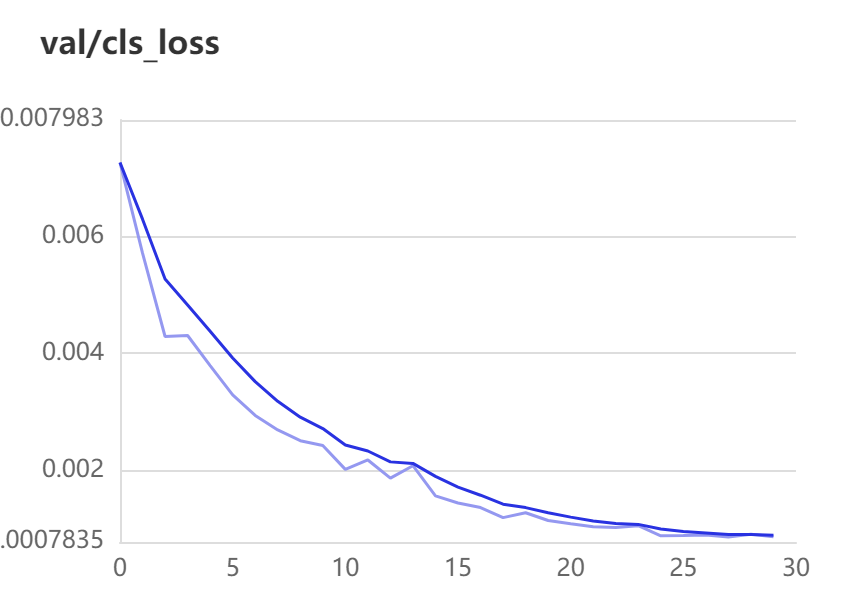
最后一个是类别带来的误差,也就是cls带来的loss
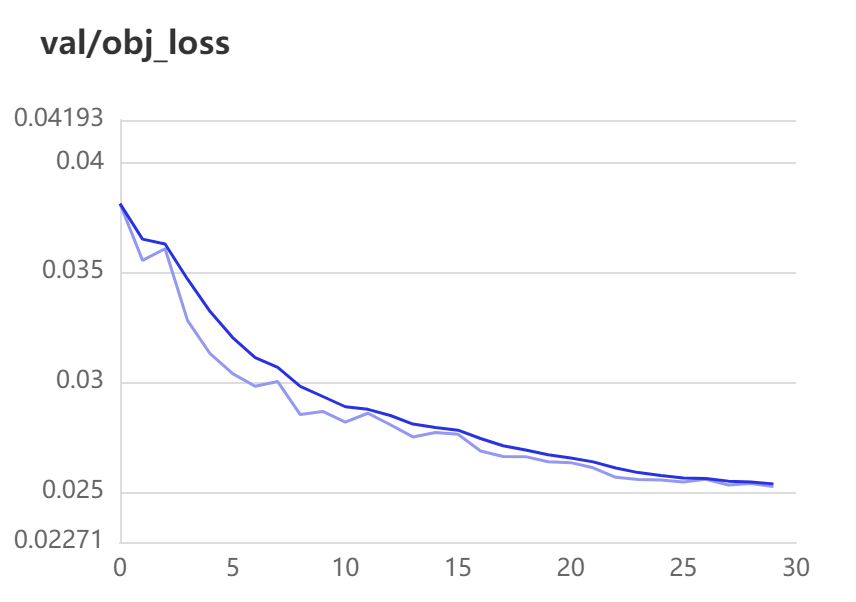
val-loss:
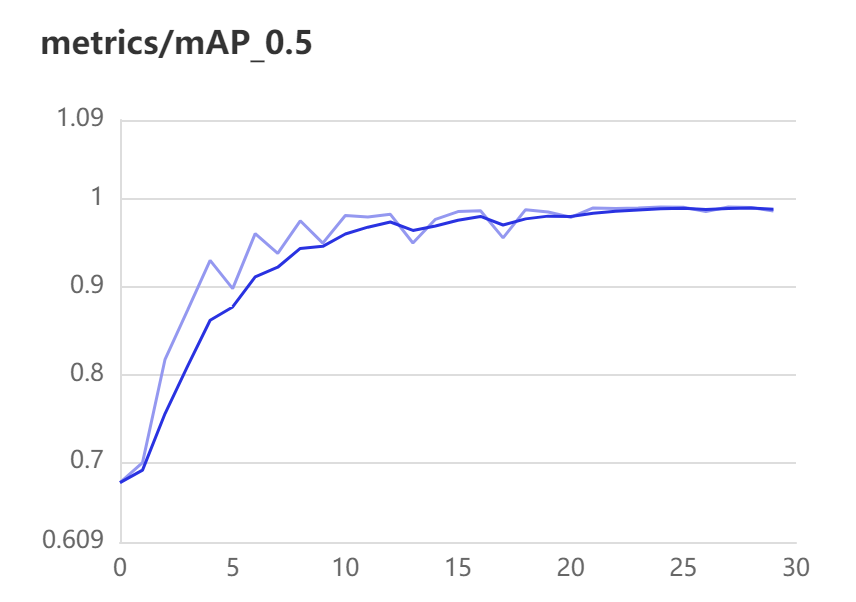
mAP.5:
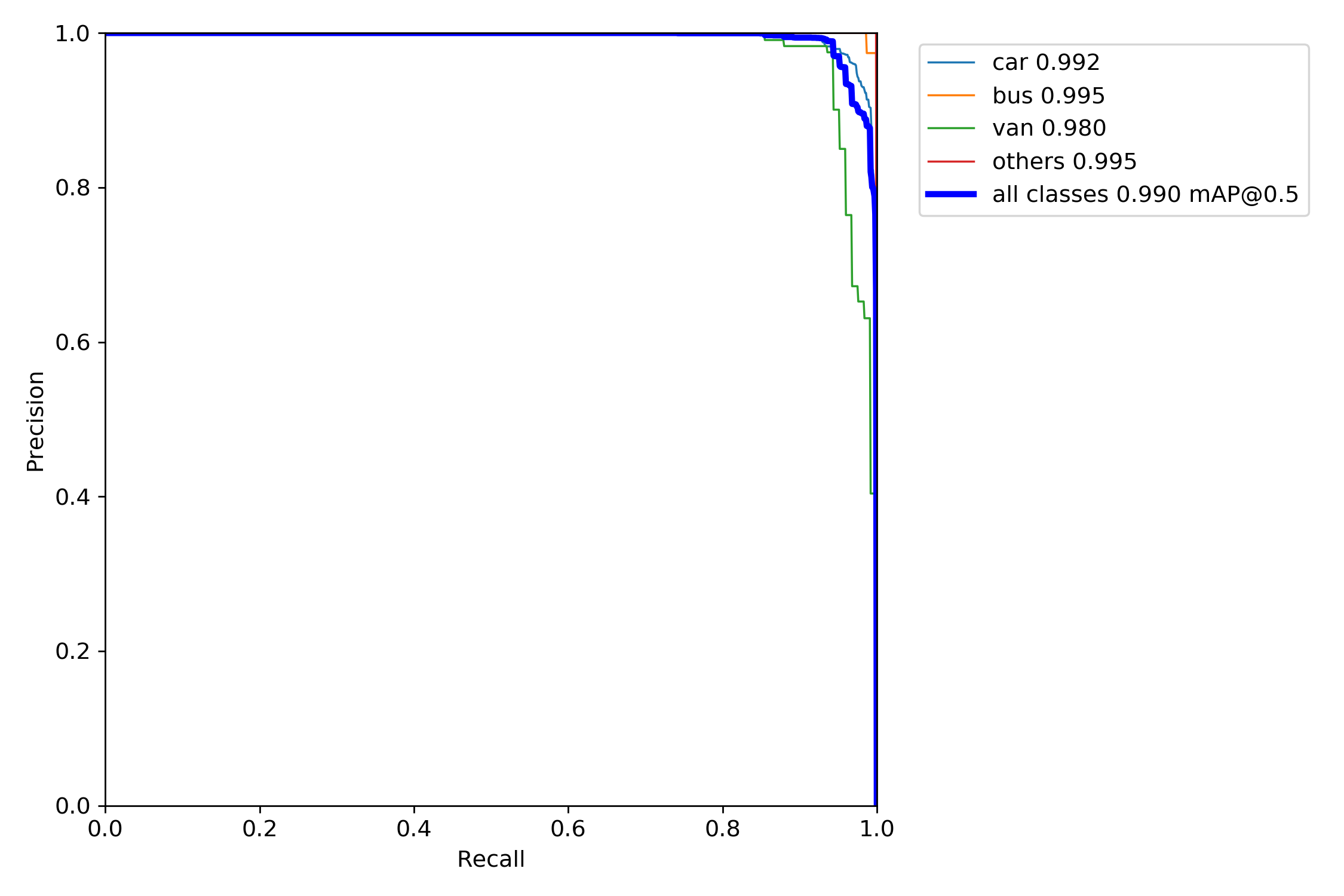
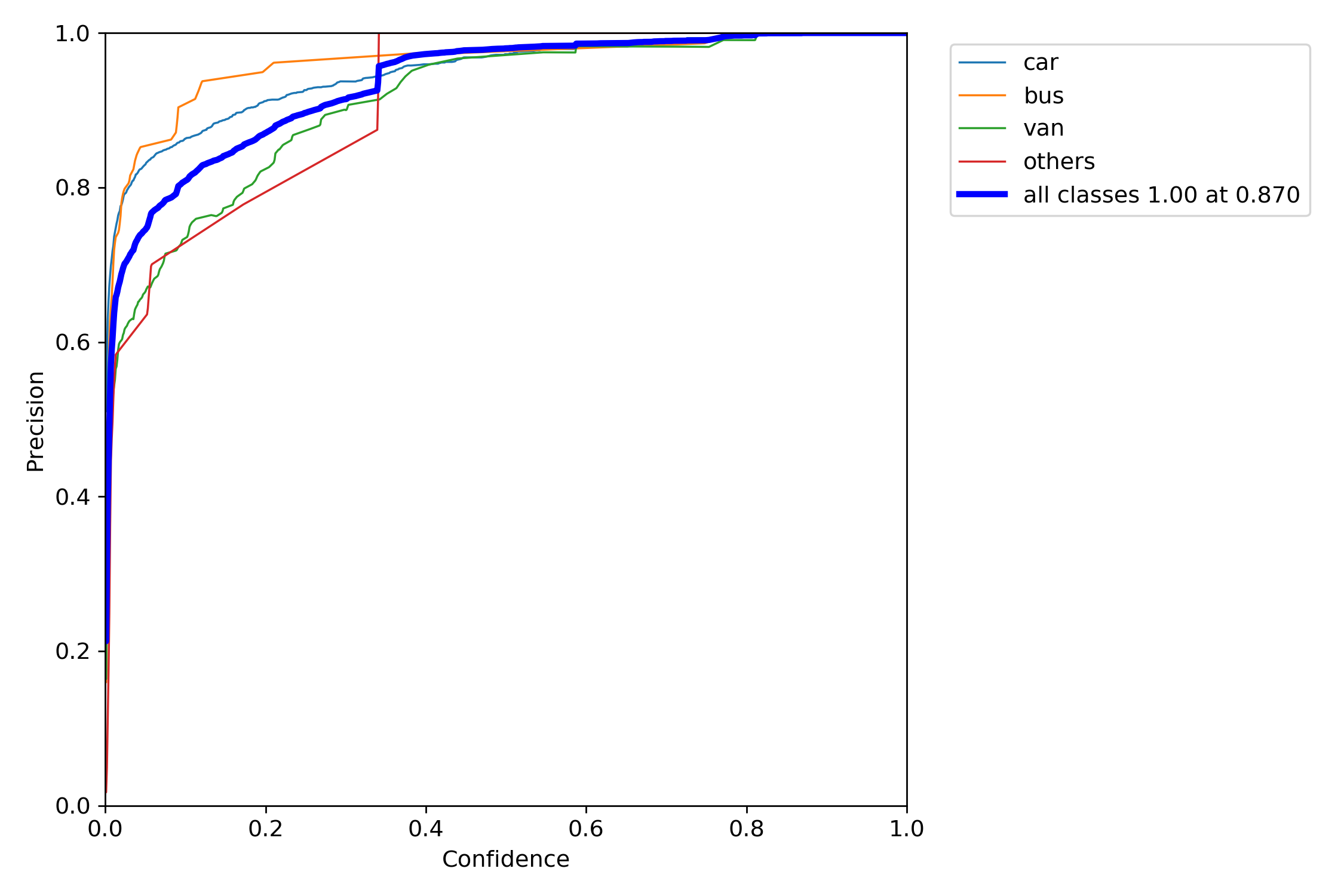
mAP:Mean Average Precision,即每个类别分别计算AP,然后Mean平均。AP即Precsion-Recall Curve图中PR曲线所围成的名字。
那么PR-Curve图怎么才算效果好?要看曲线是否平滑,多个类别的时候,哪个类别的曲线在上方证明哪个曲线的效果更好。
mAP@.5其实就是将IOU设置为0.5时,计算每个类别的AP的平均值。
IOU即置信度,目标检测评价函数,当真实框与我们的预测框完全没有相交的时候,IOU=0;当IOU=0.25时证明真实框与我们的预测框有相交部分,当IOU=1时则证明我们的预测框和真实框完全重合。一般来说,IOU>=0.5即认为检测到了目标。
PR图:
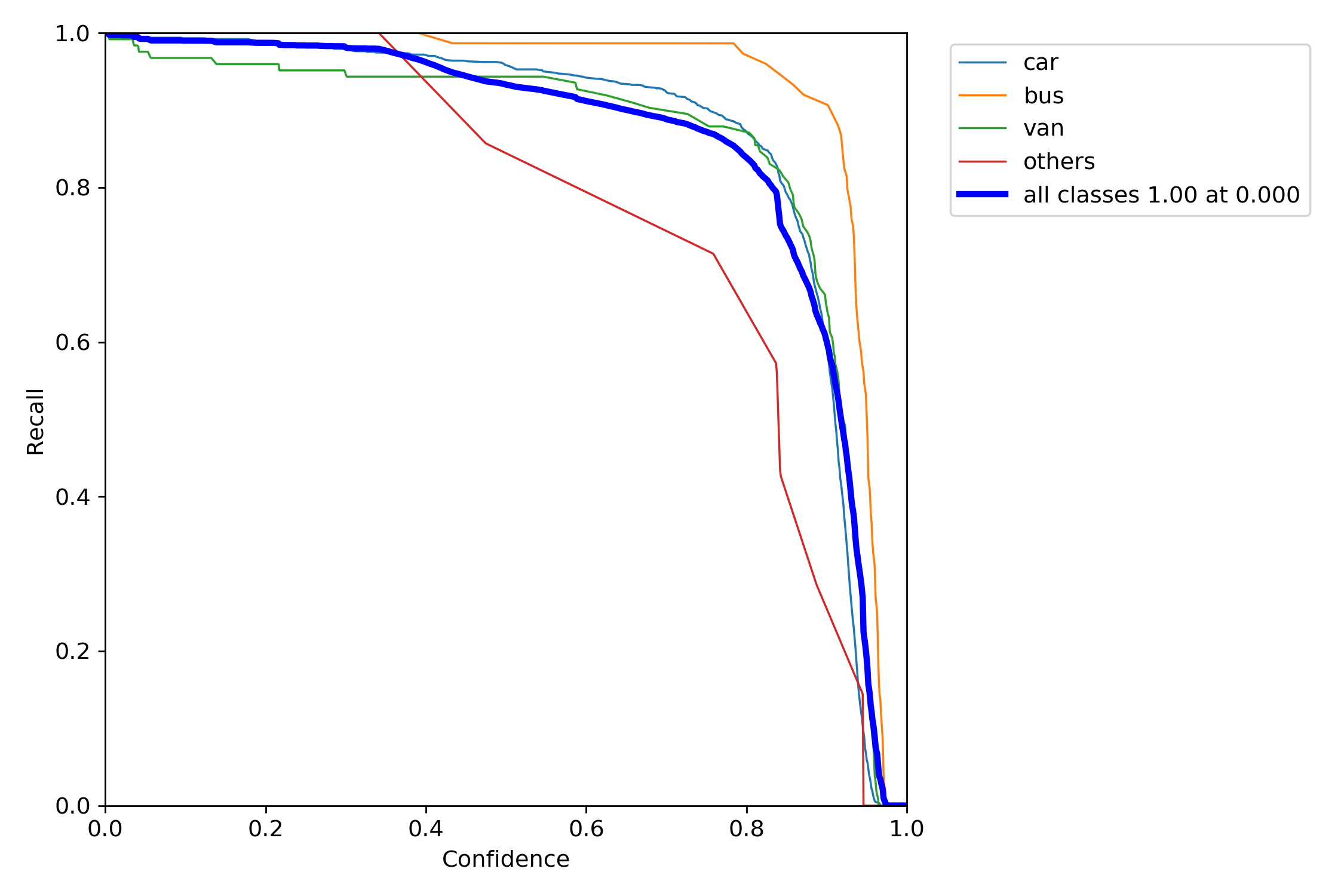
R图:
P图:
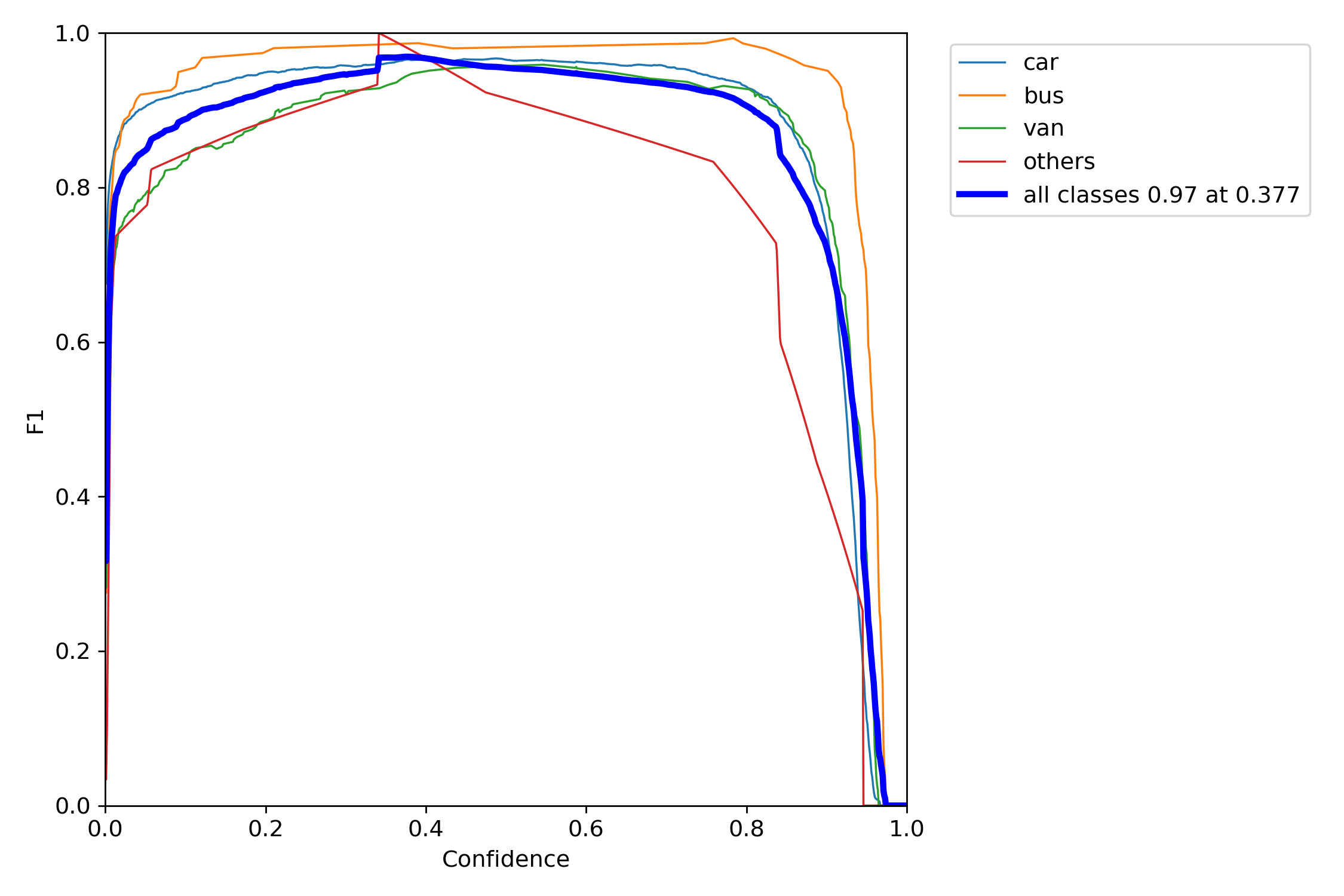
F1图:
同样,使用如下的命令即可进行数据的验证:
1 2 %cd /home/aistudio/work/ !python val.py --img 640 --data ./data/vehicle.yaml --cfg yolov5s.yaml --weights ./runs/train/exp2/weights/best.pdparams
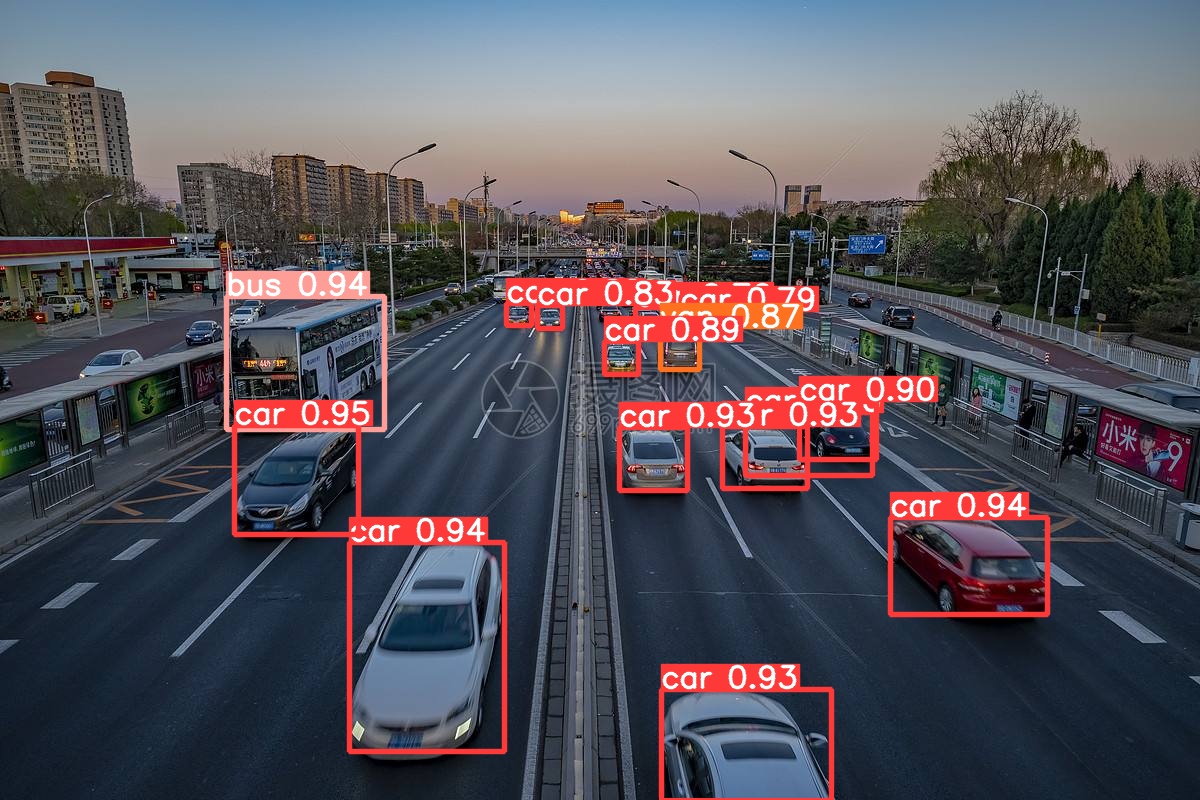
测试结果
效果还是不错的
PS. 原始项目中,对比了yolov5的源码,绘图部分应该不是ai studio不支持的原因,而是在metrics.py的plot_pr_curve(px, py, ap, save_dir=’pr_curve.png’, names=())函数中,for i, y in enumerate(py.t())编写错误,修改为for i, y in enumerate(py.T)后可以正确绘制PR图
end☆~